

Dive Brief:
- Google’s Gemini outpaced competitors in a test of 10 popular AI models created by software company Vero AI. OpenAI’s GPT-4 was second best, with Meta’s Llama 2 rounding out the top three, according to the research published earlier this month.
- The model evaluation assessed the effectiveness and transparency of algorithms, among other metrics, by reviewing publicly available documentation using human experts and an AI-powered analytical engine, Vero AI said in the report. The company’s data collection cut-off was in January, prior to the release of Gemini’s latest models.
- The company created a framework called VIOLET, which stands for visibility, integrity, optimization, legislative preparedness, effectiveness and transparency. The average scores for the 10 models, which also included Amazon’s Titan Text, Anthropic’s Claude 2 and Cohere’s Command, ranged between 76 out of 100 and 81 out of 100.
Dive Insight:
Comparing the performance of large language models isn’t a standardized science. Each evaluation has its own set of metrics to track.
“When you start to think about this task of evaluating those 10 models, it’s not like you can just go to each of these companies' websites and download a single document that clearly lays out all these things,” Vero AI CEO Eric Sydell told CIO Dive. “For each of these models, there could be 100 different links and documents, blog posts, white papers and responses to FAQs. We’re talking [about] thousands of pages strewn about the internet.”
While no model received a perfect score, Vero AI noted that larger AI providers likely have created more documentation, leading to potentially higher scores in this kind of analysis. Other factors could have played a role in scoring as well.
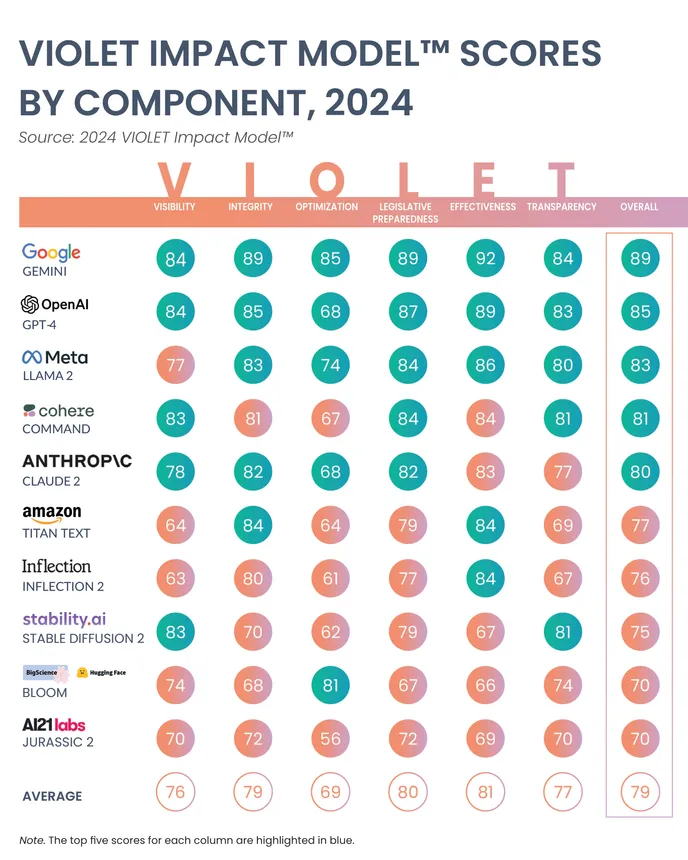
“It seemed like the closed model providers did a better job of providing thorough and comprehensive documentation, maybe because they’re in control of it and can do that easier,” Sydell said. “Whereas maybe the open ones have a lot more people involved and it becomes more difficult to find that information just by virtue of the fact that it’s more open.”
Google has started to reap the benefits of its AI model development focus. CEO Sundar Pichai credited higher demand for AI services as a driver of the company's rising cloud revenue. Earlier this month, the company released the 1.5 version of its Gemini Pro model under public preview. The company also embedded an earlier version of Gemini into its productivity suite.
It’s up to CIOs to determine which models can perform the best at the specific use case they’re targeting. But it’s not easy.
Gathering the necessary information is time-consuming, anecdotal reports of model behavior can contradict available research and customizing analysis for use cases can become complicated.
Model behavior can also change over time, requiring CIOs to continue system monitoring after deployment.
Governments are trying to step in to add transparency and improve enforcers’ ability to accurately measure systems. The U.S. and U.K. are collaborating to develop tests for advanced AI models and build an approach to AI safety testing as part of an agreement signed by both nations earlier this month.






